



Data analytics is a complex process that demands time and effort from data scientists. From cleaning and prepping data to performing data analysis, data scientists go through an extensive procedure to uncover hidden patterns, identify trends, and find correlations in data to make informed business decisions.
The task of integrating, cleaning, and organizing data assets often take up the bulk of the data scientist’s time. After all, in order to extract quality insights and engage in effective decision-making, you need clean, quality data. And not only that, you also need a unified view of all the different data source systems across your organization.
This requires an effective master data management strategy, which when done manually, can be equally as time-consuming. To streamline integral parts of this process, organizations are adopting automated strategies such as machine learning. This way, you can fast-track and automate data matching, data cleansing, and data preparation workflows; boost productivity; and continue to achieve objectives at a timely pace.
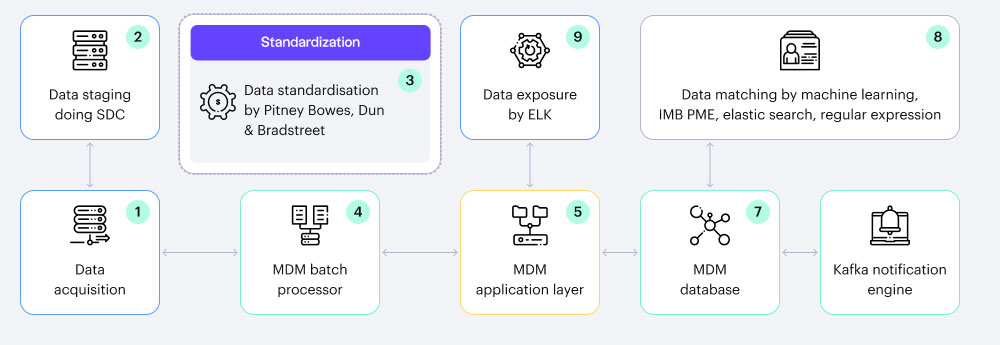
Why do organizations need master data?
Before we talk about the role machine learning plays, let’s cover the aim of master data management first. Consider a customer data platform (CDP). We created a CDP with the goal of unifying customer data from several source systems, but we ran into the following business challenges:
- Customer information is fragmented, duplicated, and inconsistent across multiple systems.
- There is no trusted view of a single customer profile for customers across various segments.
- Information is, for the most part, product-based which makes it difficult to recognize customers in their entirety.
- There is a limited ability to up-sell, cross sell, enhance systems, and improve processes due to the current IT system’s complexity.
- It is challenging to deliver a bundled products and services strategy, which relies heavily on a customer-centric view.
To create a 360-degree view of the customer, we needed a comprehensive master data management strategy to create a trusted record, golden record, or MDM record. And not only that, we also needed data governance. This is a process foundation to understand the nature of data, understand patterns, and understand business processes, which can in turn help the data team build algorithms to form consistent, unduplicated data for enterprises.
We had the data and the resources but only limited time. This is challenging especially if you’re working with massive amounts of data. In our case, we were dealing with almost 20 million accounts, more than 200K business customers, and nearly 20 different source systems to bring the data to MDM.
Data governance helped us put rules around data standardization and helped us identify critical data attributes, which can be used for matching. Typically, an enterprise uses name, email address, and other business attributes for customer data, but with data governance, we were able to add many other attributes for matching.
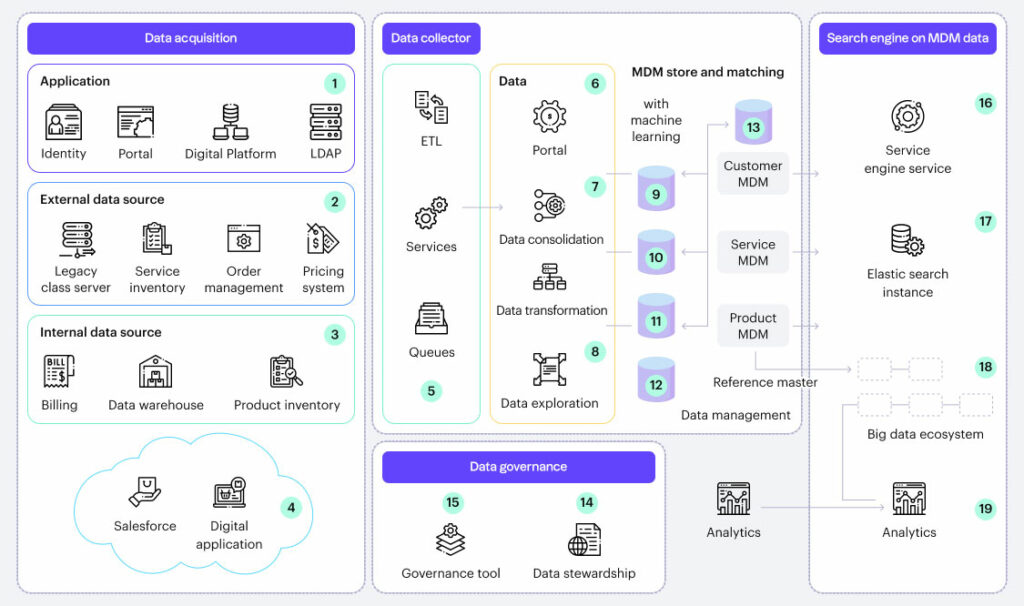
Automating MDM matching through Machine Learning
To understand MDM with machine learning, you need to understand the concept of data matching. It refers to the task of identifying, matching, and merging data records of the same entity from one or multiple data warehouses.
Basically, it is the ability to identify duplicates in large data sets. These duplicates could be people with multiple entries in one or many databases. With data matching, not only can you isolate these potential duplicates, you can also facilitate certain actions such as merging them into one single entry. You can also identify non-duplicates, which are equally important, because you would want to know that two similar things are not the same.
The traditional data matching approaches like deterministic matching and probabilistic matching do yield results, however, they can be very manual and time-consuming. By inserting machine learning into the mix, data matching can happen in a more accurate and faster manner. Machine learning provides a greater control over data and an opportunity to study and understand it.
Some of the key components of this process are:
- Standardization providers to standardize data.
- NLP usage to standardize data.
- Classification Machine Learning Models for data matching.
- Ensembled Machine Learning approach for better accuracy.
- Apache Spark for power processing.
- Elastic Search for first-level matching and data bucketing.
- Java/Python/R/SSIS support for data management.
So, how exactly does this work? Well, an organization’s current data matching process might require a black box product and manual intervention by data stewards to work on data. Generally, MDM projects are heavy and require a lot of manpower and skillsets to achieve matching with the product. They also require a lot of manual effort to clean the suspected data.
To automate this, we built Classification Machine Learning Models. The Model was built with the below ideas and steps:
- Data Sampling for Historical Data – Statistical Sampling with techniques was performed on the existing data. Stratified sampling technique was used.
- Data Standardization – Many custom rules and NLP were used to perform the data standardization.
- Data Preparation and Bucketing – The sample data was looked up into an Elastic Search instance, so as to prepare the first matching set. This process is called data bucketing. The sample data was termed “FROM” Data and the match results from ELK was termed “TO”.
- Data Preparation by Python – The sample data with bucketed results was further enhanced, where the fuzzy scores were prepared between “FROM” and “TO” keywords. Different patterns were used for matching. For example, FROM as Name + Address versus TO as Name + Address. Different fuzzy scores would then become features or predictors for our Machine Learning
- Training Data Set Preparation – The data was labelled by our testing team in order to prepare a historical data or training data set for model preparation.
- Statistical Data Analysis – The data was tested statistically to arrive at the significant predictors/features.
- Machine Learning Model – An ensemble Machine Learning Model was built using the Training Model.
- Model Optimization and Error Reduction – The Model was optimized using several techniques to reduce the false positives, hence increasing the accuracy.
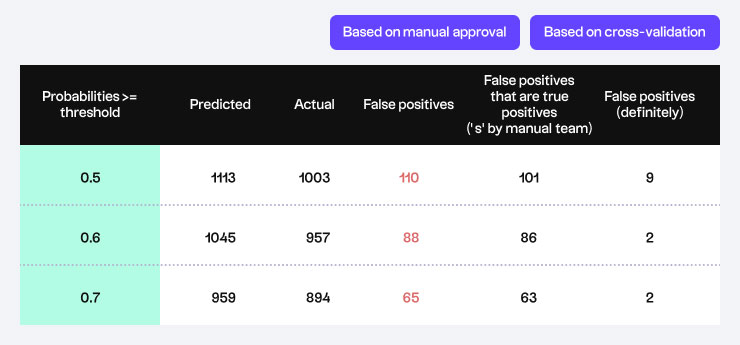
The new, incoming data was then fed to the Machine Learning Model, where the data was classified by the model into different classes (Y, N & S) and different probabilities. “Y” indicates a perfect match or in other words, a duplicate record. “N” indicates an improper match, which means the record should be discarded. And “S” means that the probability of a match is low and manual intervention is required.
The Model also provideda classification probability, which we referred to as scores. The scores vary depending on different models, built on differenttraining data sets. The current scores are probabilities ranging from 0.5 to 1. A sample test on sample data would look like below:
A more efficient way to create master data assets
Master data management can help organizations deal with fragmented and inconsistent data, facilitating deduplication to create a trusted and unified view of customers, products, services, and so on.
By incorporating machine learning into the mix, you can make the process more streamlined and efficient, freeing up your data scientist’s and other employees’ time to focus on customer-focused strategies and more proactive approaches. The results from machine learning can then be incorporated into the mix of MDM implementation styles, where our different MDM projects are on Registry and Transactional styles.



