



What do data analysis and baking a cookie have in common? Well, aside from the fact that they both produce something valuable—one being insightful information and the other being a sweet treat—both also involve following a couple of steps before the final outcome.
In the case of data analysis, there are three key tasks that need to be achieved before one can start analyzing data: data collection, data preparation, and data cleaning.
Getting started with data collection
The baking process can’t be initiated without the ingredients. Similarly, before you embark on any data-related journey, you need to acquire data to analyze first. Start by asking yourself the following questions:
- Where do I collect the data from?
- What kind of data do I need for the analysis that I am about to start?
- What kind of collection methods or channels are available to me?
There are many types of data collection: surveys, phone calls, records, forms, clinical studies, and etc. You could either get it from a primary source (the data your company collects through various means) or a secondary source (government data sets or online repositories).
Think about the goal of your analysis to get an idea of what kind of data you need to acquire. For example, if you’re looking to conduct a wage analysis, you’ll need to look at employee data, salary data, competitor numbers, and market trends, to name a few.
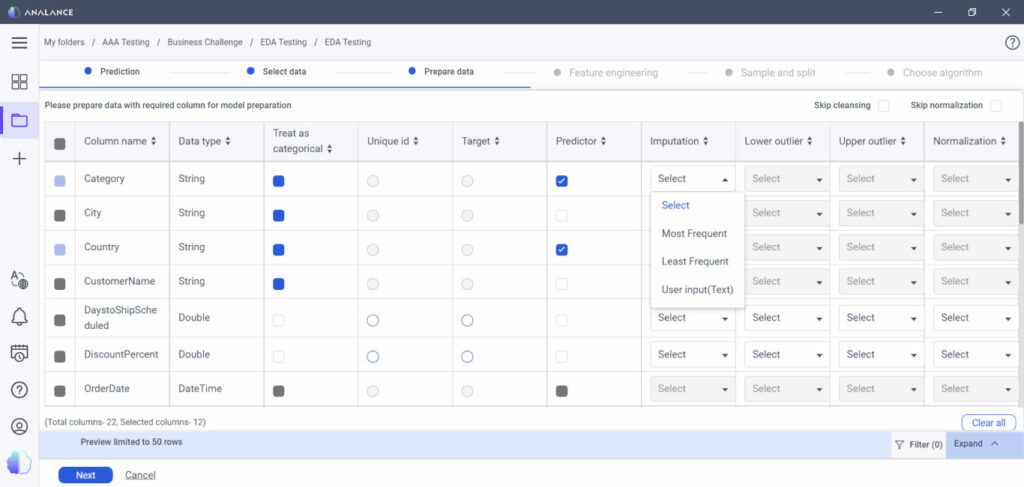
Once the data is collected and stored in a warehouse, comes the next stage of the analysis: the data preparation process. If you’re using a self-serve platform, this is the time to unify all the data in to the analytical platform in order to access it.

Why data preparation is essential
After you’ve gathered the ingredients for your cookie dough, the next step is to figure out what recipe you are going to follow to get that cookie baked. There are a couple of things that you should consider if you want your baking to go smoothly: Is the dough in the right form for you to use? Did you buy the right flour? Are the manufacturing and expiry date well within acceptable limits? Is there enough in one box for the number of cookies you need to make?
The same goes for a data analysis project as well. You need to make the necessary preparations to reduce or eliminate problems you may run into during the process. If the data is not cleaned and not in the right form, then the exploratory analysis and model will give rise to unreliable, polluted, or meaningless results. As they say: “Garbage – In – Garbage – Out”.
For example, imagine combing through salary data and finding out that 20% was entered in dollars ($ followed by a number) while the rest are just numbers. Imagine graphing that data. Not only will the results be disorganized and confusing, but they might be inaccurate as well. For all you know, the rest of the data set is in a different currency and needed to be converted first.
This is why it’s important to undergo data preparation methods first—manipulating data into a form that makes it suitable for further analysis and processing. You improve the quality of data first and this will consequently help improve the quality of results.

Data cleaning techniques
So now you’ve got the cookie dough and it seems to be in the right form—what’s next? Well, you need to make sure that it’s just dough and that there’s no adulteration. You want to bite into a chocolate chip, not a tight clump of flour, right?
In statistics and analytics, this step is called data cleaning, a process that many novice data analysts tend to overlook. Data cleaning methods involve weeding out the anomalies and unnecessary values to make sure that you’re working with an unpolluted data set.
Anomalies come in many forms but most of them belong to the family of outliers, values that lie outside of the normal distribution of the data. There are two types: upper outliers and lower outliers.
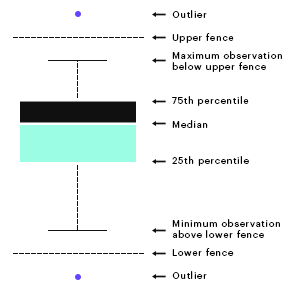
So how exactly do you determine which values are outliers in your data set? First, you’ll need to identify the inter quartile range (IQR). This is the difference between the first quarter and last quarter of the data set. Now add and subtract to this 1.5 times the standard deviation (SD) of the values to get the fences shown in the picture above.
Now you’ll have a range. Anything that lies outside the range is an outlier. More specifically, anything that lies below the IQR – 1.5*(SD) is a lower outlier, and anything that lies above IQR + 1.5*(SD) is an upper outlier.
Dealing with outliers and missing values
Let’s go back to the salary data example. Suppose your data ranges from $30,000 to $140,000 and you know that values outside these are not possible since you’re familiar with the people whose salary you’re analyzing. But then you find that 15% of your data ranges from $200 to $400, and 10% of your data falls between $300,000 and $350,000. Something’s definitely wrong here, right?
Not quite. It is possible to see such data ranges far from normality. These outliers may exist due to any of the following reasons:
- Data entry errors by humans or machines
- Actual values included but not well documented and hence falling into the outlier category
You’ve also noticed that 20% of your data is missing. So how do you deal with these anomalies in your data set?
Well, you can choose to retain these values, but you would need to use techniques that excel at handling outliers without affecting the results of the analysis, such as mathematical functions. Still, you could run into issues. Not to worry though.Outliers and missing values can either be left out of the analysis or can be, as is statistically known, “imputed”. This entails replacing the meaningless value with a meaningful or plausible value.
For example, if your salary data has 10 outliers and 4 of them are upper outliers and 6 are lower, simply replace the upper outliers with the 95th (or 98th) percentile and replace the lower outlier with the 5th (or 2nd) percentile. As for the missing numeric values, you can replace these with the arithmetic average to start a simple analysis.
There are more complex methods of imputation, but the techniques above will do the trick and will ensure that you are on the right track in your analysis.
The next step: Feature engineering and reduction
Great! The data is clean, and the road ahead looks good. What’s next? Well now, you can proceed to the main chunk of the analysis. But what happens if you’re planning to build a machine learning model and you find that you have too many predictors? 50 or so is manageable. But what if you have 1000 or more?
Let’s say you’re trying to predict global sales for a certain product. This can be affected by practically any number of factors: the day of the week, time of day, gender of the consumer, age, employment status, number of children, age of children, and so on.
The opposite also remains true. It could be that you don’t have enough variables. What if you’re stuck with, let’s say just, four? How do you know which variable to keep in the analysis and which ones to throw out, plus what form the variables should be in for a proper analysis?
Enter feature engineering and feature reduction. These are essential steps that will help get your data ready for machine learning modelling.
Feature engineering
Feature engineering involves engineering, transforming, or building features. For example, perhaps the length of a square’s side is not a great predictor of its area, but a transformed or engineered feature (such as the squared value of the side of a square) would be a good predictor instead.
This is a relatively simple example but transforming features in a similar fashion is done very often in industry applications. This helps build complex models and will highly influence the results that you are going to achieve.
Often, feature engineering depends on a combination of common sense and domain knowledge. It might also turn out to be complex and time-consuming. However, this process is fundamental to machine learning, so investing time to understand how it works will pay off in the long run.
The feature engineering process consists of the following steps:
- Brainstorming or testing features
- Deciding what features to create
- Creating features
- Checking how the features work with your model
- Improving your features if needed
- Going back to brainstorming or creating more features until the work is done
Feature reduction
Maybe you don’t need 50 predictors in your analysis. Maybe just 7 of those 50 will do to start. But how do you decide which of the 7 you should use? There are ways to get around that as well.
Feature reduction, or dimensionality reduction, is just that—reducing the number of features or dimensions to a manageable level. It reduces the risk of overwhelming your algorithms (yes, this does happen) and your audience, while simultaneously trimming down computation time.
The goal, really, is to find the most optimal and meaningful subset of your existing features while mitigating information loss or a reduction in predictive power. In some cases, analyses and models built using a reduced number of features turn out to more accurately reflect the patterns in the data. What’s more, the simplest model often turns out to be the best for interpretability and predictability.
Other advantages of feature reduction include a reduction in analysis time and storage time, removal of multicollinearity, improvement of model performance, and ease and accuracy in visualization in multiple dimensions.
Convinced yet? There are three major strategies you can use:
- Filtering, which is based on information gain
- Wrapping, which is based on a guided search emphasizing on accuracy of results
- Embedding, which is based on adding or removing variables while building the model based on prediction errors
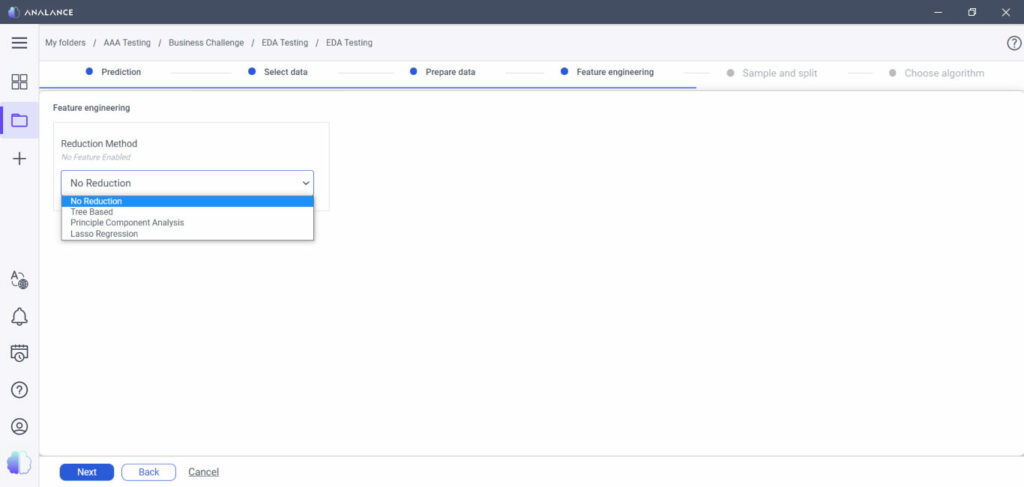
And don’t worry—a self-serve analytics platform usually comes with easy options to reduce the number of features in your dataset. For example, the following techniques are readily available in Analance:
- Decision Trees: Helps you build trees where the final optimal tree will use only those variables that contribute to a good level of accuracy and predictability
- Principal Component Analysis: Helps you decide which specific variables explains the most variation in the target or response under consideration
- Lasso Regression: Reduces the effect of redundant or repeated variables to near zero while simultaneously emphasizing the value of strong predictors of the outcome
The next step: Feature engineering and reduction
The road to a perfectly baked cookie is still a long way off, but at least you’ve put the foundations in place for a smooth journey. After all, data preparation takes up roughly 80% of a data scientist’s time. If done correctly, it will set the tone for the rest of the analysis and ensure that you come up with reliable, clean results.
For an even more efficient process, it’s best to use a self-serve analytics platform such as Analance. With built-in capabilities to help you prepare and clean your data efficiently, it allows you to get the insights you need faster and move on to the next analytical project.



