



Machine learning models are often used for decision support—what products to recommend next, when an equipment is due for maintenance, and even predict whether a patient is at risk.
The question is, do organizations know how these models arrive at their predictions and outcomes? As the application of ML becomes more widespread, there are instances where an answer to this question becomes essential.
This is called model explainability. We will explain what this concept is and when it should be a concern for enterprises.
What is model explainability?
While some machine learning models are interpretable and easy to understand, others are like a black box—the input (data) and output (prediction) are accounted for, but the inner workings of the model isn’t.
Let’s say a manufacturer needs to predict the sound pressure level in airfoil to optimize aircraft design. A decision tree regression model is built. As seen in the decision rules below, one can understand how exactly the model arrived at the predicted value.
If the frequency is less than 2,500 hertz, go down through the left node. If the suction side displacement is more than 0.03 meters thick, the model predicts that the sound pressure level is 120.7 decibels.
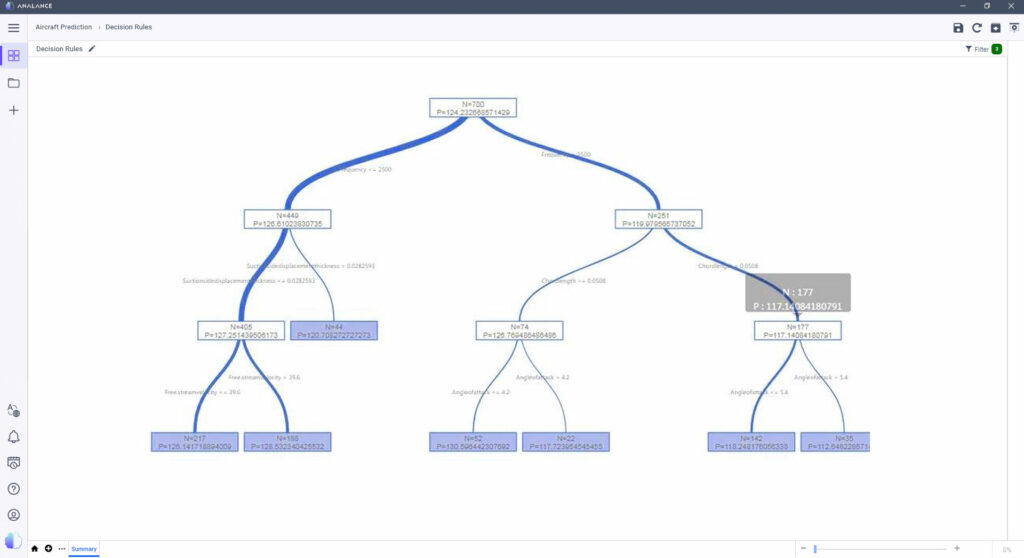
In this case, it’s entirely possible to determine cause and effect. We look at the decision tree and get a clear idea of what causes a certain sound pressure level. However, this model is fairly simple, with only a few parameters.
If one used more features or more complex algorithms—take for example image recognition—the model becomes a black box. It become less interpretable and harder to understand, and it would be challenging to explain each parameter’s significance to the final output.
Engineers often deploy machine learning models without ensuring explainability: an understanding of what each parameter signifies and how it contributes to the conclusions made. This makes it difficult to justify the decisions the model makes. However, it’s not always necessary to peer into the black box and understand its inner workings.
When is model explainability essential?
When a machine learning model is explainable, it inspires trust in the system and the output produced. This trust is critical when one wants to know what medicine is best for them but probably not as important when looking for the next TV show to binge.
Regulators have already taken some steps to require this transparency. In the European Union, the GDPR restricts high-stakes decisions that are solely automated, mandating a “right to explanation”.
In the financial industry, the Insurance Institute of Canada deems it important for insurers to explain how they arrive at underwriting decisions when leveraging artificial intelligence or machine learning. According to their AI and Big Data report, “consumers deserve to be informed about changes in their expected risk of loss, as reflected in the price they must pay for coverage.”
Black box models also come with a risk of bias and discrimination. Without explainability, it can be hard to rule out whether a model is making decisions based on a certain parameter. A Google image recognition model, for instance, was under fire for producing different results depending on the skin tone.
Simply put, explainable machine learning is necessary when the stakes are high. When the model output results in potentially great consequences, such as financial opportunities or discrimination, explainability should be something to strive for.
What enterprises can do
While not always essential, model explainability comes with a slew of benefits:
- Communication – ML engineers can justify decisions made by machine learning decision, helping others understand the model’s behavior.
- Accountability – Organizations can detect and resolve model bias and other gaps in the models and data.
- Maintenance – With visibility into the significance of parameters, debugging and improving model performance is more streamlined.
- Deployment – As one of the common roadblocks organizations face in deploying models, explainability can help optimize MLOps and production.
Fortunately, there are steps organizations can take to understand how models arrive at their conclusions. One such technique is feature importance. Determining feature importance can help approximate how each model parameter contributes to the final output or prediction. The higher the score, the more significant the feature.
For example, let’s say a telecom organization is trying to forecast incident call volume using the random forest algorithm. As seen in the visualization below, province, service type, and device type are the top three variables in predicting the number of incidents. These contribute to about 61% of the data prediction.
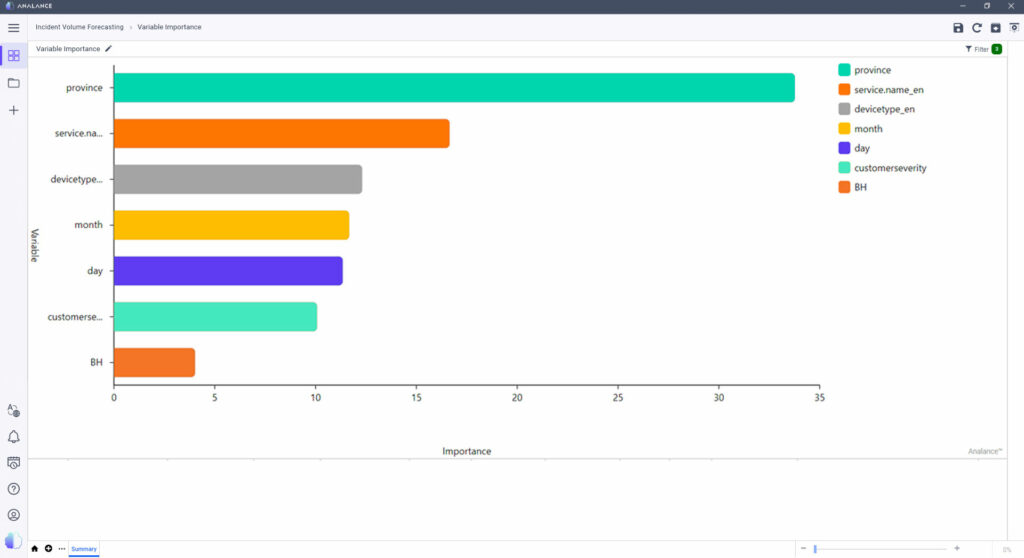
It’s important to note though that standalone results like this should be taken with a grain of salt. Model explainability is more reliable if achieved using a variety of methods such as model-agnostic techniques LIME and SHAP or DeepLift for deep learning. Combining these with extensive experience and domain knowledge would produce more accurate, reliable results.
Build trust and transparency in machine learning
As AI and ML continue to advance, organizations looking to succeed in the space must be prepared to face the responsibilities that come with this innovation. While explainability remains a core problem that is being actively solved, there is no doubt that it will soon become a competitive edge as the technology is used more and more for decision support—high stakes or not.



