



Predictive analytics is a complex process that involves many steps and procedures—from collecting and preparing data to communicating findings through eye-catching dashboards. But there’s one stage that data scientists enjoy doing more than others: predictive modeling and algorithms.
As an integral part of data science, modeling involves building a solution, mining the data for patterns, and refining algorithms. In short, it’s the heart of any advanced analytics project, and it’s the key to the final output: a machine learning model that turns data into predictions and actionable insights.
The predictive analytics modeling process
Predictive analytics is a proactive approach used by many organizations to extract value from historical data. Depending on the business challenge, you can use the insights gained to forecast outcomes, optimize processes, engineer solutions, and generate recommendations. Basically, predictions facilitate better decision-making and outcomes.
For example, in an industry like banking where the risk of fraud is rampant and costly, you may want to get a better idea of what might characterize a fraudulent transaction. With this information, you can predict the presence of fraud and implement proactive measures to mitigate losses.
But first, you’ll need to build a predictive model that provides you with this foresight. Let’s take a look at the steps involved in this process.
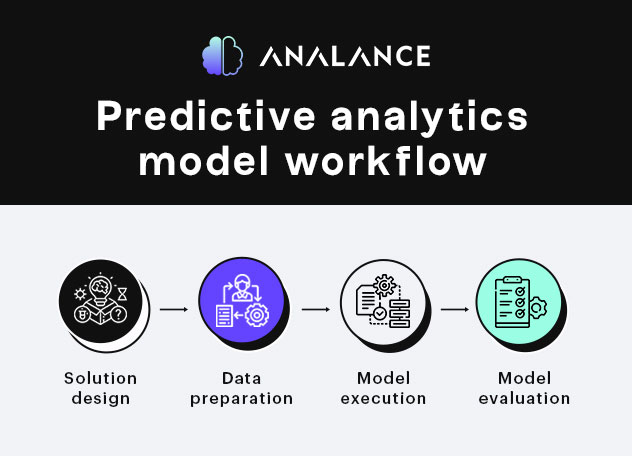
1. Solution Design
So you want to build a predictive model. After you’ve identified the business challenge and collected the required data, you’ll want to get into the nitty-gritty of the solution. Identify exactly what problem you’re trying to solve, figure out how to translate the data you have into the answers you need, and determine the success criteria.
Let’s go back to the banking example. Here, you want to detect patterns in past fraudulent transactions to accurately predict the presence of fraud. There are many algorithms used in machine learning, so defining the parameters of your solution will help you make the right choice.
In this case, because you know what the output value should be (presence of fraud), you may opt for a supervised machine learning algorithm, where a model is trained on a pre-defined set of data for it to make a prediction. And because you want to determine whether transactions are fraudulent or not, a classification algorithm is recommended.
2. Data preparation
Now that you’ve framed the problem, it’s time to get familiar with the data available. A crucial part of this is preparing data for analysis. You need to get data into the right shape and format to ensure the quality of results. As they say: garbage in, garbage out.
This is also the time when you need to define the variables for the algorithm. In supervised learning, the goal is to develop a finely tuned predictor function. As a result, given input data (for example, transaction amount), the predictive model will be able to provide an accurate predictor function / output (in this case, likelihood of fraud).
So, you need to determine what data will be used as input. Your dataset likely has attributes such as transaction type, transaction amount, or customer ID that can be used as input parameters. Perform a univariate analysis to check the distribution of each variable and a multivariate analysis to determine relationships between other variables.
These steps will allow you to determine significant columns and features for further analysis.
3. Model execution
Next, you need to split your data into a set of training data and a set of test data. It’s worth noting that predictive analytics is founded on statistics, so during this step, it’s important to select a statistically significant random sample as training data. The key term here is random. For example, when predicting fraud, you can’t draw an accurate conclusion from training data that contains large-amount transactions only.
As the name suggests, the training data set will be used to train the algorithm and develop the predictive model. Typically, this will include 50% to 80% of the data. The test data set, on the other hand, will be used to validate the model and see how the predictions compare to the actual data. This typically includes 20% to 50% of the data.
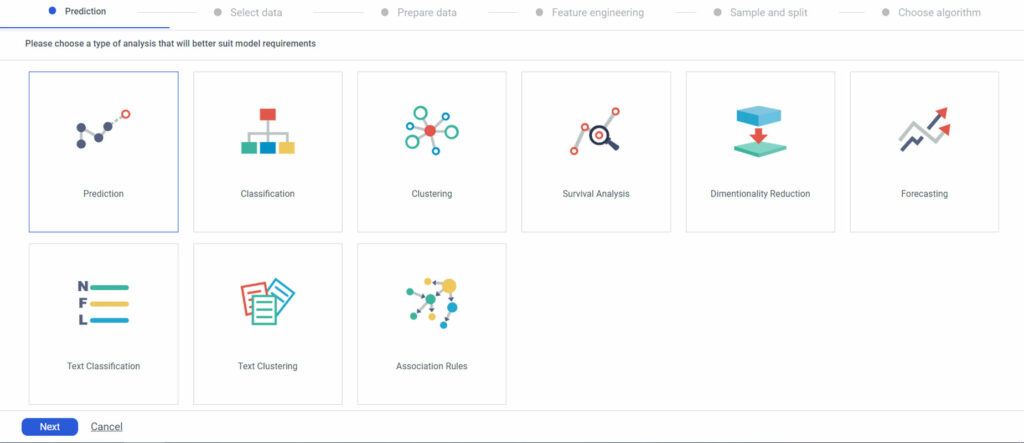
Once that’s done, you can train and build the machine learning model based on the target column or business challenge. Based on the analysis type (Prediction, Classification, Clustering, etc.) and nature/type of the predictors, you can choose the relevant ML algorithm/s and build your model.
In this case, as there are many types of classification algorithms, you can run the analysis on an ensemble mode to obtain better predictive performance.
4. Model evaluation
Now that the model is built, you want to check for its robustness and stability. This is done by scoring and predicting using the test sample data set. Here, you’ll see how the predicted values compare to the actual data. In short, you’ll see whether the model correctly or incorrectly predicts actual fraudulent transactions.
You can check the model performance using a variety of metrics, such as accuracy, which is the fraction of correct predictions; sensitivity (recall), which refers to the correct classification of fraudulent transactions; specificity, which refers to the correct classification of non-fraudulent transactions; and more. If you ran the analysis in an ensemble mode, you can identify the best-performing model for deployment too.
Time to make predictive analytics magic
We’ve outlined the steps to building a predictive model, but it’s important to note that the process might not be linear at times. Machine learning often requires you to redevelop, tweak, or reuse models, so it’s always going to be a constantly evolving process. But as data volume increases and business challenges become even more complex, predictive analytics will always be a reliable tool to acquire valuable, actionable insights.



