



Service Level Agreements (SLAs) are commitments given to customers in relation to the product or service being provided. If breached, not only are organizations expected to compensate through penalties and credit fees, but they can also face a significant dip in brand reputation and loss of customer trust.
This is why preventing SLA breaches is a top priority for any customer-facing organization. To stay on top of breaches, agents traditionally check the ticket status of each incident manually. But this process is laborious, time-consuming, and risky—in fact, it’s easy to miss a potential breach. Read on to learn how you can optimize and automate this workflow using machine learning.
Leveraging ML to prevent SLA breaches
A fortune 500 telecom organization was experiencing a high number of SLA breaches and customer complaints. To help them reduce this number, we implemented a ML-powered alert system that flags tickets nearing an SLA breach using Analance.
Sourcing and preparing the data
We used the telco’s 2019 incident management data to identify variables or predictors that are significant in predicting SLA breaches. There was a total of 659,875 tickets with 78 attributes such as creation date, device type, description of the ticket incident, and day of the week. Only user-created incidents for specific services were considered for analysis.
To effectively categorize tickets, a text clustering analysis was conducted using the data from the descriptions provided by customers. Five ticket clusters were identified: SNMP tickets, test tickets, Wi-Fi tickets, DNS/VLAN tickets, and tickets on router and other connection issues. These clusters were then included as a predictor for the machine learning model.
Data then went through the usual cleaning methods, plus a Univariate and Bivariate Analysis (Chi-squared) so that analysis is restricted to only significant predictions.
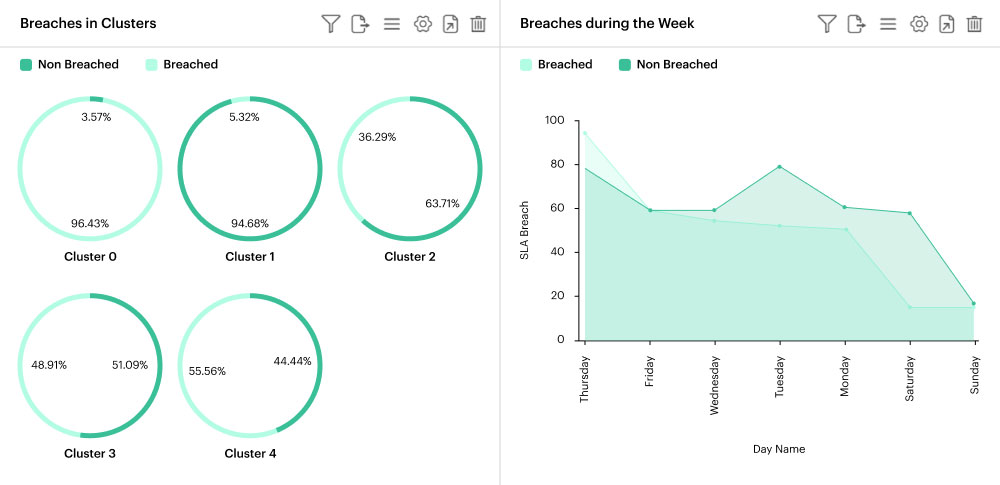
Building the machine learning model
To train and score the SLA breach prediction model, we used classification algorithms like Random Forest, Naïve Bayes, K-Nearest Neighbor, Support Vector Machine, and Decision Tree. Training was done in an ensemble mode and went through different iterations until the output was satisfactory. If the data distributions deviated significantly from the original data set, the model would be retrained.
We utilized libraries in Python—sklearn, nltk, pickle, and more—to implement the algorithms, and we leveraged natural language processing to save the trained models. To help improve model performance, categorical columns with textual data was encoded using the LabelEncoder function. We had to make sure that the different levels in each categorical variable were consistent for both the training and scoring stage.
To illustrate, we had a column pertaining to the day of the week in which the ticket was created. During training, this column contains only Monday, Tuesday, and Wednesday as levels. Now if the scoring data contains levels other than those 3 days, we would get an error in the code. This was fixed by storing the trained models in a pickle file and using this to score the new data.
Model results
Analance has 41 prebuilt machine learning algorithms, with 8 categorized as classification algorithms. We used an ensemble approach to train the model and analyzed the results to identify the best performing one.
To visualize the performance of the model, we used the ROC plot. The area under the curve value is 0.69, which means that there is a high chance the model is able to distinguish between breached and non-breached tickets.
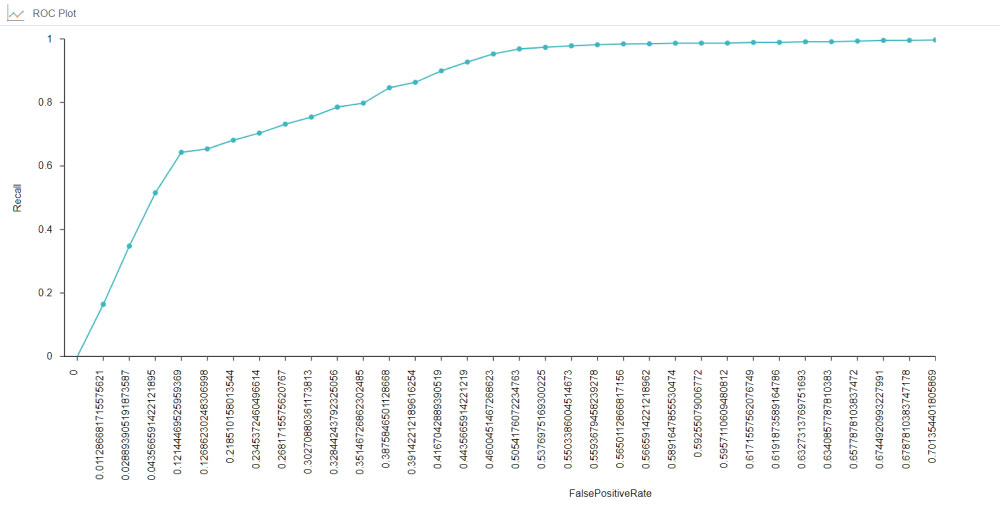
Sourcing new data
The model built was used to score new data in 2020 with favorable results, as seen in the confusion matrix below.
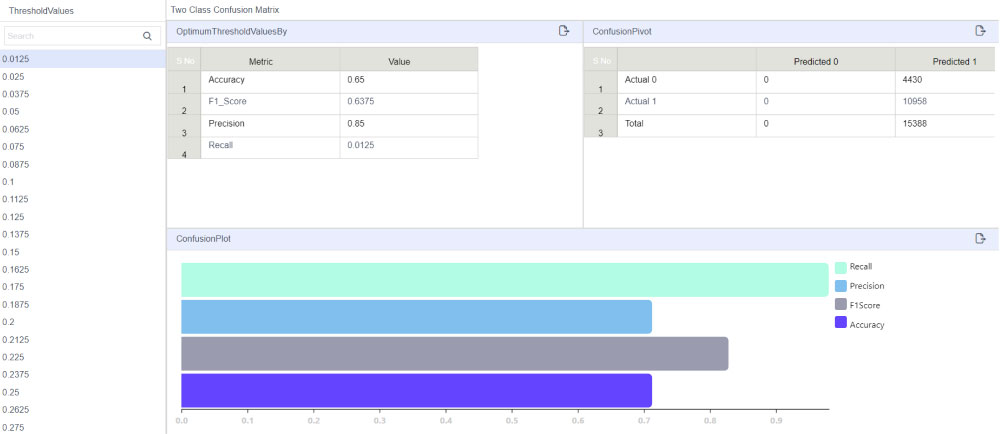
In the table, the rows represent the actual values and the columns represent the predicted values. For example, for the first value, 73.97% represents the percentage of ‘0’ (non-breached) tickets that have been classified as ‘0’ (non-breached).
This means that 73.9% of non-breached tickets have been classified correctly. Similarly, 72.6% of breached tickets have been classified correctly. As for misclassification, the rate is only about 26% for breached and non-breached and 27% for non-breached as breached.
Streamlined workflows, happier customers
The prediction system can be used as an alerting system—tickets with a high likelihood of being breached would be tagged in an interactive dashboard that is updated in near real time. Agents or technicians can simply consult this report to prioritize high-risk tickets.
Furthermore, the NLP-powered clustering system that groups similar tickets can be used to optimize the incident resolution process. When working on new tickets, agents can use insights from historically similar incidents and replicate the resolution method where applicable. There would be no need to refer to the knowledge base every time to solve a ticket.
Lastly, the predictive engine can help in resource allocation as well. The machine learning model can determine specific time periods when a large number of incidents is expected. By anticipating this spike of potential SLA breaches, managers can plan accordingly and make sure that qualified agents are available whenever there’s a higher risk. Managers can also consider the foresight into potential number of false positives to keep expectations in check.
With foresight into potential breaches, the telco organization was able to facilitate timely resolution of tickets, prevent breaches from happening, and reduce the Mean Time to Repair (MTTR)—boosting customer satisfaction and trust in the process.



